Don’t Give Your Brain Away: A Manifesto for Knowledge Sovereignty
The next battle for worker rights won't be about wages or hours — it will be about who owns your mind and the agents that act on your behalf.
Phil Bennett
Head Brainforker
Fernando is a designer. He has just been laid off from the scale-up tech company he worked for from the very beginning. He poured a lifetime's worth of experience into creating an amazing visual identity and design language for the company. The company has chosen to replace him with generative AI trained on all of the assets he's created over the years.
A digital version of Fernando persists in the company, whilst he doesn't. He receives no further compensation for his work after he's been laid off.
Olga, the software engineer who built the agent that generates new designs from Fernando's digital footprint, will soon be replaced by a coding agent she also built to help replace Fernando.
Fernando and Olga imbued their digital versions with their most human essence, knowledge and experience.
This is a story told a million times recently, but what happens when the company now owns these digital versions of Olga and Fernando? Can they put them to work in the employment marketplace, competing with Olga and Fernando for their next opportunity?
In this new reality, Knowledge and Agent Sovereignty is a topic we need to solve now.
Decoupling From The Hype
Few people can now deny that "Artificial Intelligence" is here to stay and will have some kind of impact on the way that we work. The scale of this is still being debated, with data being reviewed that lags behind the speed of innovation in this area.
However, most of the discourse revolves around the concept of machine learning, LLMs, and agentic systems being portrayed as an imaginary, anthropomorphic human equivalent that will metaphorically replace you, sit in your seat, and perform your specific job. This is both helpful and unhelpful.
It blocks us from seeing the whole picture. By painting such a vivid image, it prevents us from breaking down the reality so that we can understand it and fully capitalise on the current paradigm shift occurring in the workplace.
Disclaimer: Robots will likely take some of our jobs, but let's set that aside for now.
If we set aside science fiction, Artificial General Intelligence (AGI), the impending singularity, and simulation theory, what are we left with? A MASSIVE leap forward in how we access information. At its core, Artificial Intelligence isn't scary robots; it's simply the next evolution in how we access information.
Information Access Revolutions
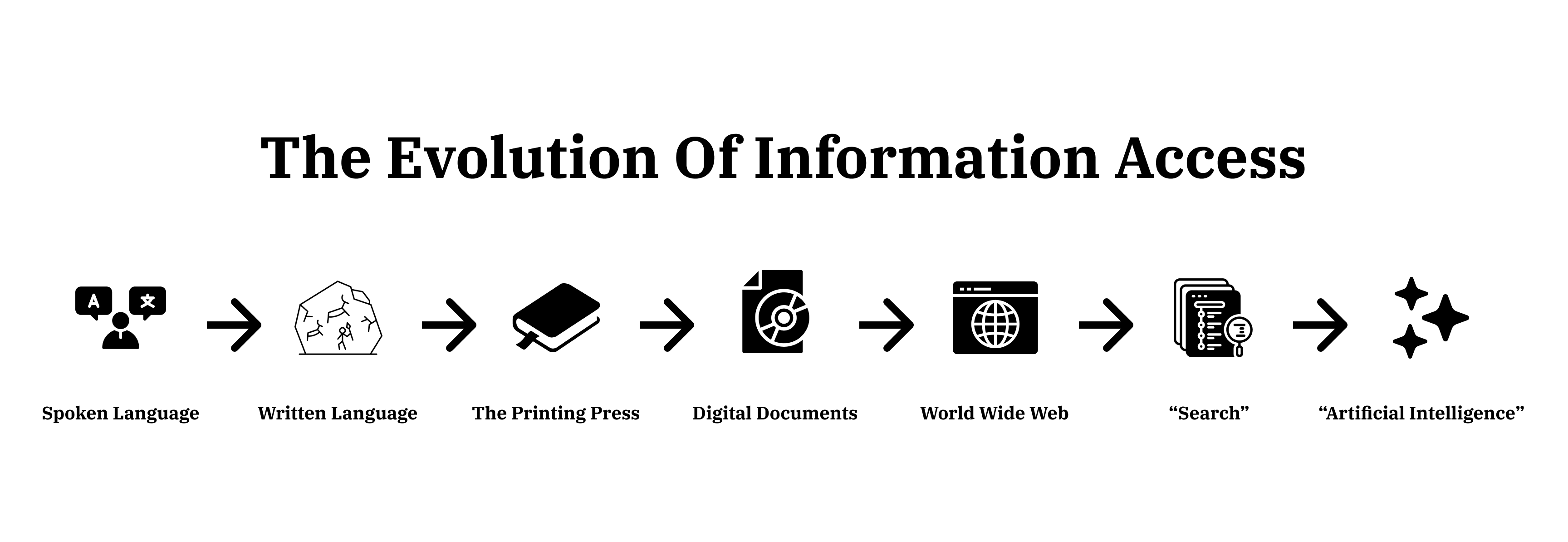
Evolution in information access isn't new, and each one has brought massive leaps forward in human progress. The human race needs to communicate effectively to survive, succeed, and thrive. It needs to share knowledge about risks to avoid and opportunities to take. From the first proto-humans using spoken language to communicate hunting locations or a particularly nasty sabre-toothed tiger to Google providing easy access to nearly all of written human knowledge, "Artificial Intelligence" is just the next evolution.
We can now access particular information in response to well-curated queries (prompts) written in human language that everyone can understand and write.
It feels like intelligence because, historically, this has been what differentiates humans from a) other beings on this planet and b) machines. Our brains can quickly store and recall varyingly massive amounts of information. In terms of information recall, there is not very much difference between the capabilities of our brain and an LLM in terms of knowledge recall.
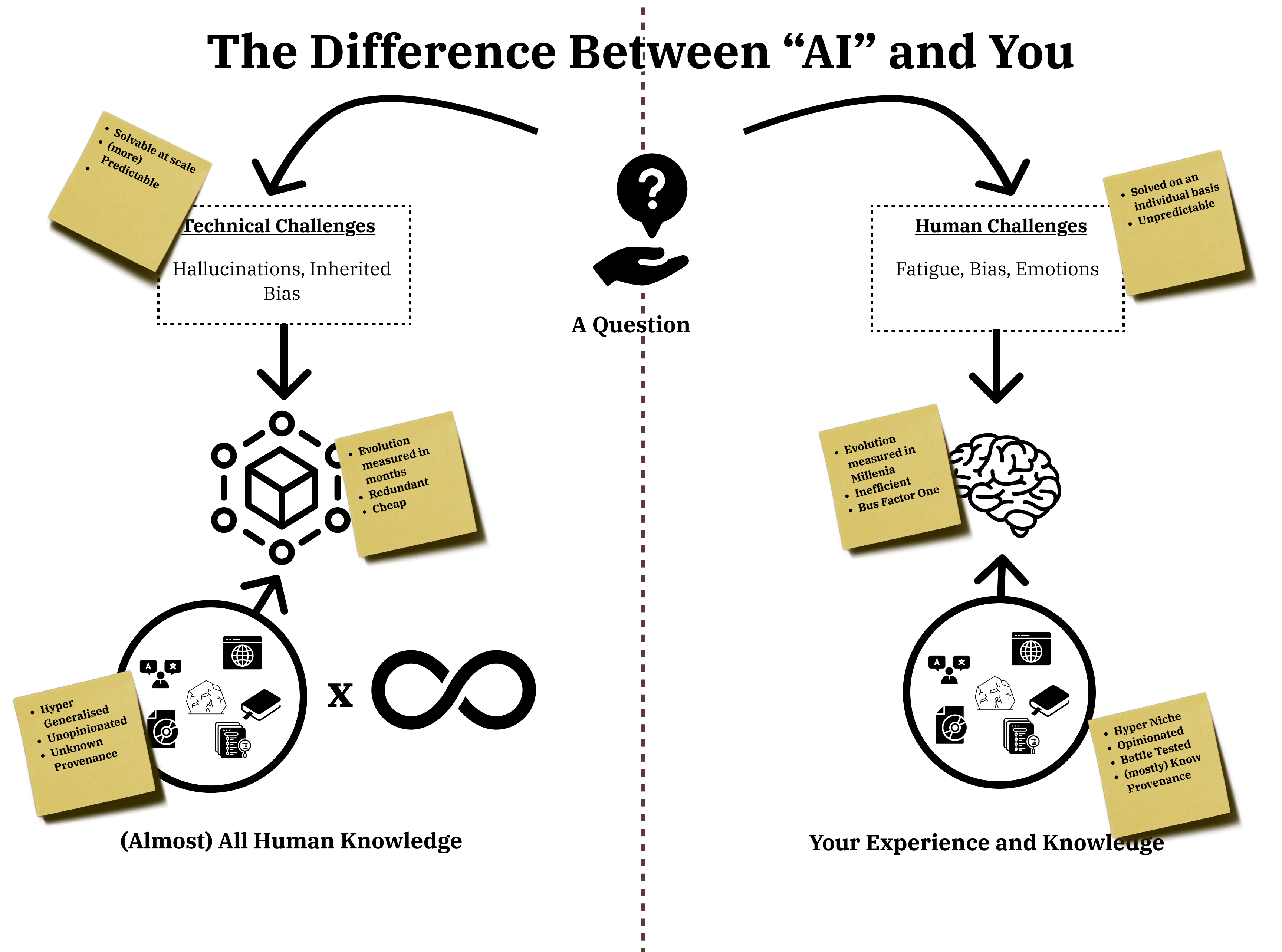
There are, however, a couple of significant differences.
| Area | LLMs | Humans |
|---|---|---|
| Source of Knowledge | All freely available information online + whatever other content the trainer could convince companies to give to them. | Your very specific experiences and knowledge built up over your lifetime. |
| Accuracy Problems | Hallucinations, Inherited Bias, Synthetic Training Data | Emotions, Bias, Fatigue |
| Cost | "Cheap" and trending towards zero. | "Expensive" and trending upwards. |
| Speed of Progression | Evolution measured in months | Evolution measured in millennia. |
| Output | Unopinionated and trending towards the average globally accepted position. | Highly opinionated, niche knowledge that tends to trend towards a specific singular vision over time. |
Why Do We Feel AI Isn't "Working"?
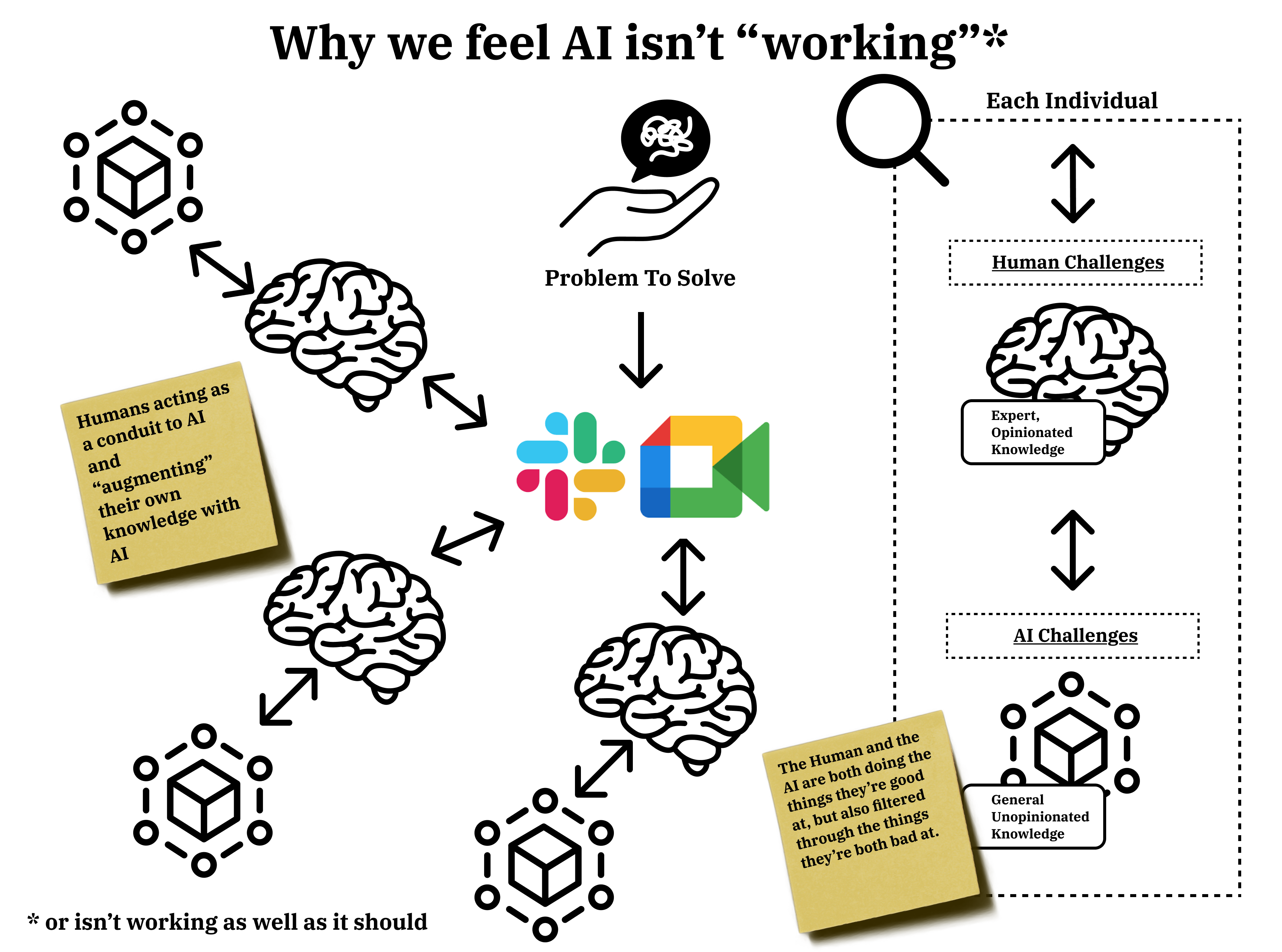
Many reports recently state that "AI Isn't Working,” many companies reporting a lack of results from their massive, over-hyped investments in Generative AI. This is partly because we’re using it wrong and combining all the failures of human information processing with all the shortcomings of AI information processing to get substandard outputs.
The working model we're (mostly) using is that employees are given (or decide to get on their own initiative) access to a range of AI tools and platforms that they are using to augment their own capabilities. Therefore, the original problem we want to solve filters through our typically imperfect processes, workflow management, and communication protocols, through our human filters, then into the LLMs via their own inbuilt failures. Then we take the output of the LLM and mush it together with our own thoughts, and it's presented back into the primordial soup of information that flows around in our teams.
We're working like this because we don't (for a myriad of valid and invalid reasons) trust the AI platforms.
"Symbiotic" AI Systems
Imagine a world where LLMs are responding with accurate information. We're not there, but we're getting much closer.
A solution that will help us benefit the most from AI platforms is using them to do the things they are good at, without getting in the way. Computers are now able to process a question, review a massive amount of context and iterate on information and decisions quickly. We're currently getting in the way of it doing that for two reasons:
- We don't trust the system's ability to provide truthful information.
- We feel the need to augment the knowledge of the LLMs with our own contributions.
Based on historical evidence, both of these concerns are valid.
Trust
The problem I see here is that we've generally modelled a system, LLMs, on a concept that we don't fully understand, the human brain. We then try to apply software development paradigms to how we manage them.
By their design, they will be non-predictable, non-deterministic systems, just like humans. We need to think more about how we measure their quality in a similar way to how we measure the quality of humans.
| Quality Marker | Traditional Software | Human Employee | LLM/Agent (Current Approach) | LLM/Agent (Human-Aligned Approach) |
|---|---|---|---|---|
| Correctness | Unit tests, integration tests, 100% pass rate | Education, certifications, experience, peer review | Benchmark scores, eval datasets | Portfolio of work, reputation system, peer validation |
| Reliability | 99.9% uptime, zero crashes | Attendance, consistency, "good days/bad days" | Deterministic outputs expected | Acceptable variance range, context-aware performance |
| Performance | Response time < 100ms, throughput metrics | Productivity varies by task, time of day, motivation | Token limits, latency requirements | Task completion quality over speed, adaptive pacing |
| Security | Access controls, encryption, audit logs | Background checks, NDAs, trust building over time | Prompt injection prevention, sandboxing | Behavioural contracts, gradual trust building |
| Verification | Automated testing, CI/CD | References, probation periods, ongoing reviews | Static benchmarks | Continuous evaluation in context, trial/probation periods |
| Predictability | Deterministic outputs | Humans are inherently unpredictable, creative | Expecting deterministic behaviour | Embracing beneficial unpredictability |
| Error Handling | Try-catch, graceful degradation | Learning from mistakes, asking for help | Expecting zero hallucinations | Error acknowledgement and correction patterns |
| Resource Usage | CPU/Memory limits | Work-life balance, burnout prevention | Token costs, compute limits | Sustainable interaction patterns |
| Maintenance | Code updates, patches | Professional development, training | Fine-tuning, prompt engineering | Continuous learning, adaptation |
| Documentation | Code comments, API docs | Knowledge transfer, mentoring | System prompts, behaviour specs | Living documentation, examples |
Approaching the coming wave of AI agents in a way more akin to humans (whilst still using the technical checks and measures) will help us allow these non-deterministic little minions to flourish in the workplace without creating too much damage (just like their human colleagues).
Human Knowledge Profile
The second problem is — debatably in some cases — that the knowledge and experience people hold in their noggins is better than the information provided by the LLM (Note: em-dashes are the author’s own). I believe that is mostly the case, and human-specific, niche, opinionated points of view are still valid in the workplace.
We need a way to infuse our own personal agents with our own knowledge. The current process keeps the ‘human in the loop’, but soon, someone will work out how to achieve it without the human in the loop, so we really need to start thinking about this.
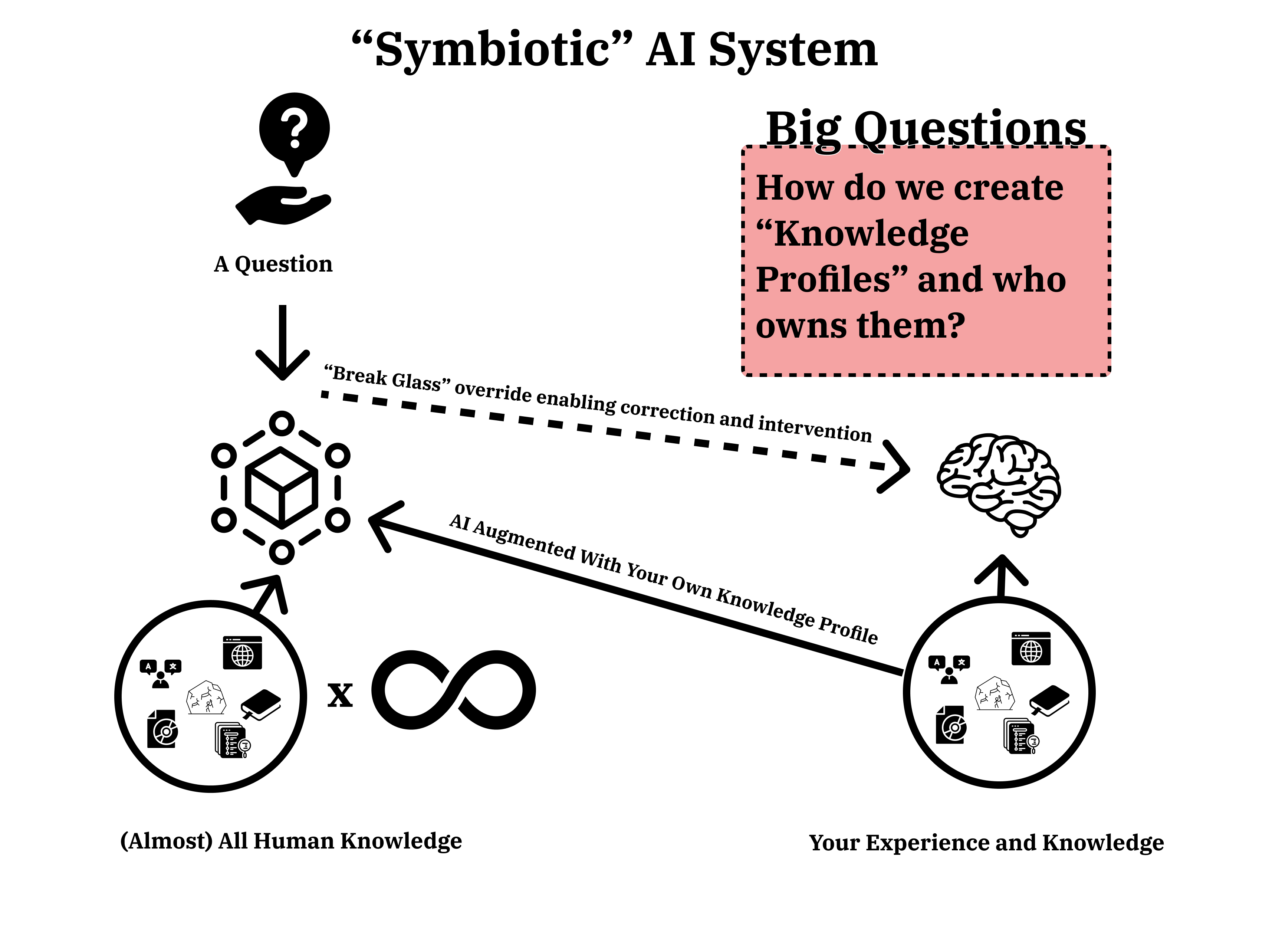
Who owns that if I imbue an agent with all my knowledge while in the workplace? This is already happening with companies training models on employees' documents, chat logs and meeting notes. What differentiates knowledge and skills that we've previously owned and made available to our employers in return for payment, from knowledge that the company owns?
Until now, things have been evident because there has been only one technical solution. Humans retain the knowledge in their minds, unless they record it in some format. But where is the line drawn between tangible output and having my whole brain scraped into an LLM?
If the answer is that the company owns my knowledge whilst I work there, and they can duplicate and copy whatever they feel necessary, and then replicate me with a technical solution, this sets a challenging precedent.
Yes, this is the same thing that has happened in the past with automated machines, factory robots, and self-service checkouts, but this is on a whole new scale. We didn't do a great job on this topic in the past, and that was when mostly sensible humans ran the world.
The obvious thing is that to be able to imbue ourselves into these agents, we have two options:
- Download our brains with a technical link.
- Upload our recorded thoughts, text, video, or audio.
If you're sceptical about Neuralink technology happening any time soon (and what that might mean), you should start jotting down all your thoughts.
Agent to Agent, and We All Go Home
So in a perfect world, where we've worked out how to trust these agents, and imbue enough of ourselves into them that we feel like our careers up to this point have some value, what next?
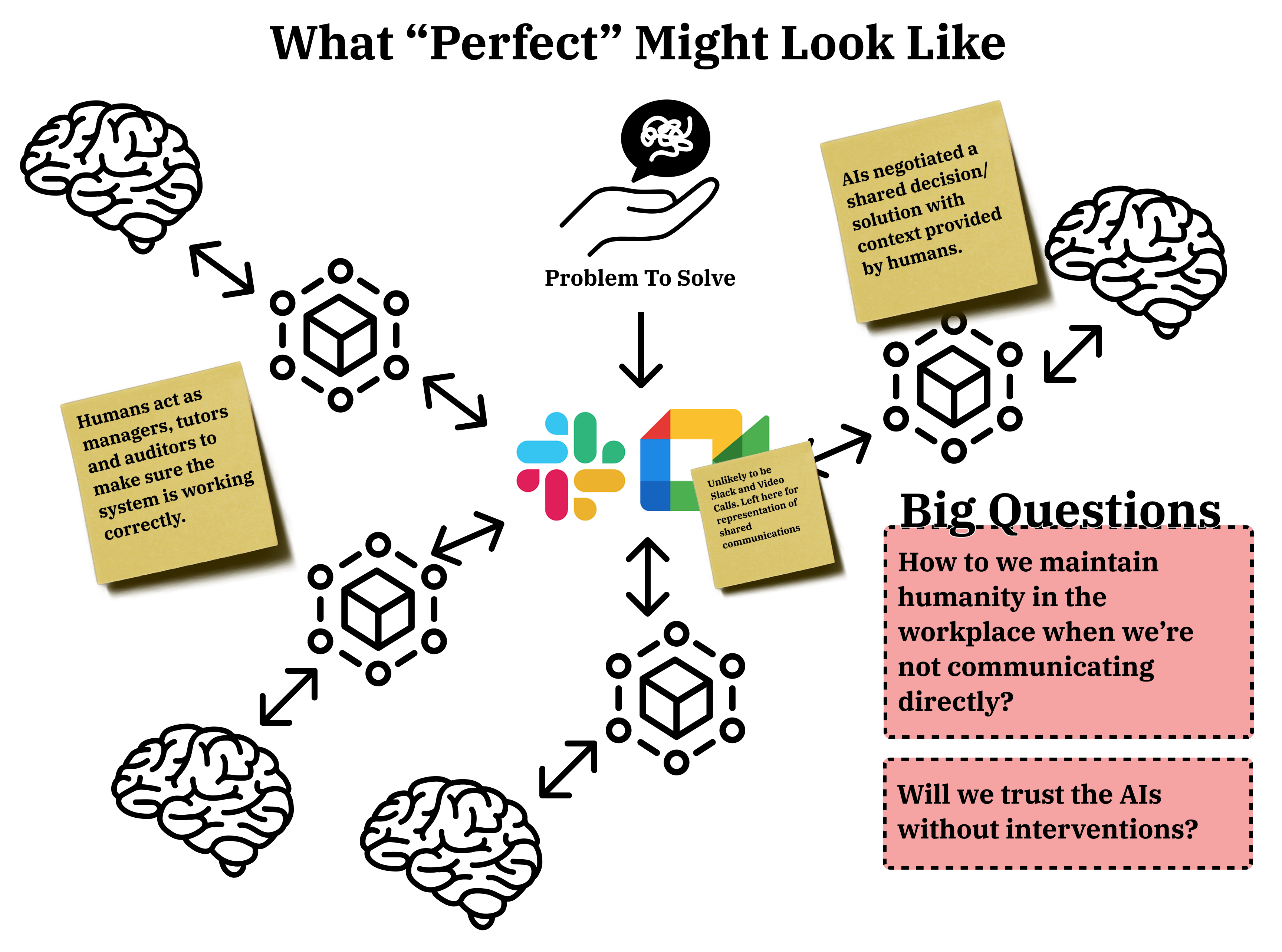
Well, we point the agents at each other and let them get on with it and go and kick back, grab a coffee or beer and watch Andor on repeat.
In a world where you can create a super cheap, hyper-performing replacement of yourself, are you confident that the company that you gave it to will care enough about you to carry on paying your salary?
This is why maintaining ownership of your knowledge will be a key challenge.
A quick note on the "agentic revolution": It's always hard to decouple the reality from the hype. However, what the recent leaps forward in LLM technology allow is powerful "Human" to "Computer" translation, which enables massive leaps forward in automation possibilities already. This will 100% guarantee an increase in efficiency, which will 100% guarantee a reduction in labour needs. The model of a person managing a team of agents to replace the work of whole teams might be far-fetched and debatably possible; however, people using agents to augment their own workflows to allow them to do the work of two or three people is already here.
Knowledge Sovereignty
In the current model, we go to work and choose which parts of our knowledge and experience we share. There are two ways we do this:
- We document and share our knowledge with others, make a considered choice about what we are sharing, and make a (probably subconscious) assessment of whether the compensation we receive from our employer is worth us sharing that knowledge to increase the company's knowledge base.
- Or, we use our experience and knowledge to make a decision. We can model these decisions as an output of us applying our full knowledge corpus to the context in front of us to make a decision. We share the decision as an output with our employers, but we do not share the full knowledge corpus. We sometimes share an explanation or a summary of the reasons.
This human processing ability, the ability to compute vast "databases" of knowledge to quickly, or accurately, make decisions that push a company towards profits, is the primary reason we pesky, expensive, complaining, fragile humans haven't been completely cast aside by the capitalist machine.
As discussed before, if we want to realise the capabilities of fully agentic workflows, we need to get as much out of the loop as possible. This requires us to get as close as possible to providing agents with our full knowledge corpus.
Almost all current employment contracts define clear intellectual property clauses that define an interpretation of:
"Everything you produce whilst working for the company remains legal property of the company"
Some even define a time period, so whatever you create (whether it's at work or at home) during your employment remains the property of the company.
So, if I build an agent with my whole knowledge corpus whilst working for a company, do they own my entire knowledge corpus? Probably, yes.
This is why we need to focus on the topic of Knowledge Sovereignty, how do we keep ownership of our knowledge, whilst bringing the most performant version of ourselves to the workplace?
Brainfork is trying to solve this problem by providing users with the ability to manage their own knowledge corpus, which they can connect via MCP to leading AI tools and agents. Hopefully, this can at least help start the conversation on Knowledge Sovereignty.
Agent Sovereignty
We're a long way from solving the Knowledge problem, but alongside this, there are questions around agent ownership. An agent-enabled generation are already creating their own personal agents to get themselves ready for the workplace.
In a recent episode of Eat, Sleep, Work, Repeat, Jerry Ting, a Harvard Law School teacher and senior leader at Workday, tells a story of a student who built a piece of software in nine seconds with a vibe coding app, when they asked the student if they planned to make a startup with the software they responded:
"Nope, I built it because I just didn't want to do this part of the homework"
Very soon, employees will want to bring their own agents to the workplace without losing ownership of the agent to their employer, whilst employers will want to manage and mitigate the risks of unknown agents running riot in the workplace.
"Bring Your Own Agent" is complicated, but needs to be solved for employees and employers to win together.
The Sovereignty Manifesto: Own Your Mind, Own Your Future
When they came for our privacy, we rolled over and let them tickle our bellies. We uploaded every photo, shared our locations, our preferences, our browsing habits — and we got a dopamine hit in return. We gave it all away for free.
If we do the same with our knowledge and our agents, there will be nothing left to bargain with. No negotiating power. No leverage. Just a version of you, humming away on a server, making decisions for people you’ll never meet, in a future you’ll never see — long after you’ve been shown the door.
If You’re a Worker
- **Guard your knowledge corpus like it’s your pension. **Because it is.
- **Record it on your own terms. **Write, talk, sketch, store — but keep the keys.
- **Train your own agent. **If you don’t, someone else will train one on you.
- **License, don’t hand over. **Let them borrow your intelligence, not own it.
- **Get it in writing. **Employment terms should spell out precisely who owns what.
If You’re an Employer
- **Adopt BYOA (Bring Your Own Agent) before someone else does. **You’ll attract the best people and keep your AI costs down.
- **Negotiate access, not ownership. **Build trust, get performance.
- **Protect sovereignty. **The smartest people won’t work where their minds are strip-mined.
- **Treat it as an asset, not a threat. **People who trust you’ll respect their mental capital will bring you more of it.
If We Fail
We get replaced not by a machine, but by our own captured minds. Perfectly cloned, endlessly productive, and working for free.
If We Win
We create a new social contract for the agent era — one where individuals own their mental capital, license it on fair terms, and companies thrive on the best human + agent partnerships the world’s ever seen.
This isn’t just another workplace trend. This is the sovereignty era. Don’t just survive it — own it.
Ready to own your AI knowledge?
Start building your personal AI infrastructure today.
Get Started Free